-
[R] 랜덤포레스트(Random Forest )통계방법론 2019. 7. 19. 14:06
머신러닝 기법을 사용할 일이 있었는데, 그 중에서 나는 Random Forest를 맡게 되었다.
사용해본 적이 없어, 혼자 공부하고 적용해본 예시를 공유코자 한다.
랜덤 포레스트는 주어진 데이터로부터 여러 개의 모델을 학습한 다음, 예측 시 여러 모델의 예측 결과들을 종합해서 사용하여 정확도를 높이는 기법 중의 하나다. 특히, 랜덤 포레스트는 분석 도구로서 의사결정나무 모델을 사용한다. 즉, 랜덤포레스트란 여러 개의 의사결정트리를 만들고, 투표를 시켜 다수결로 결과를 결정하는 방법이다.
1. 장점
1) 개별 의사결정나무가 과대적합을 만드는 단점을 해소할 수 있다.
2) 특별한 매개변수 튜닝 없이도 높은 정확도를 가지고 있다.
2. 단점
1) 의사결정나무와 비교하였을 때, 예측 과정을 시각적으로 보여주기 어렵다.
2) 대량의 데이터셋에서 훈련과 예측이 느리다.
3) 텍스트 데이터와 같이 차원이 높은 데이터셋에서는 잘 작동하지 않는다.
정리한 내용은 이러하고, 예제 파일을 보자.
먼저 사용할 Data인 Boston data를 살펴보기 위해 "MASS"패키지를 설치한다.

Boston 데이터는 아래와 같이 생겼다.

해당 자료는 Boston 지역의 집값(medv)과 관련된 변수들을 종합한 자료인데, 이번 포스트에선 "회귀 랜덤포레스트(Regression random forest)"가 아닌 "분류 랜덤포레스트(Classification random forest)"를 소개할 예정이므로 해당 자료의 전처리를 먼저 할 것이다.
내용으로는, 타겟 변수인 짒값을 quantile에 따라 4개의 Ordinal variable로 나누는 것이다.

medv.q라는 변수명으로 기존의 medv를 4개로 나누어 새로 만들었다. 분포는 아래와 같이 나왔다.
대체로 균일하다. 그러면 본격적인 Random forest를 시행하기 전에 기존의 자료를 더 다듬어보자.

medv.q 변수생성 전에 존재했던 medv변수를 지우고, 새로 만든 변수를 Numeric variable에서 Ordinal variable로 변환하였다.
이제 본격적으로 Random forest를 만나보자.

위의 코드를 차례대로 읽어보면
set.seed(1) #시드를 1로 잡고, (랜덤포레스트이므로 랜덤한 상황을 가정하는 데, 그 랜덤 상황 중 '1'이라는 상황을 가정하자는 얘기)
train <- sample(1 : nrow(Boston), nrow(Boston)/2) #전체 Boston 자료 중에 반절은 train data로 쓸 예정
이후로는 randomForest라는 패키지를 불러오고 실행하는 코드이다.
여기서,
class.rf <- randomForest(medv.q~. , Boston, subset = train, mtry=13, importance = TRUE )
의 인수를 좀 뜯어보면,
medv.q ~. #이는 곧 medv.q를 종속변수로 하고 나머지 모든 변수를 독립변수로 보자는 뜻
Boston #Boston 자료를 대상으로 할 것
subset = train #이전 코드에서 1/2만큼 샘플링된 데이터였던 train으로 학습을 진행할 예정
mtry = 13 #노드를 나눌때 고려할 변수의 수로, 본 예제에서는 독립변수의 수로 적용하였음
importance = TRUE #변수별 중요도를 따로 적용하겠다는 의미
인데, 결과를 보자.
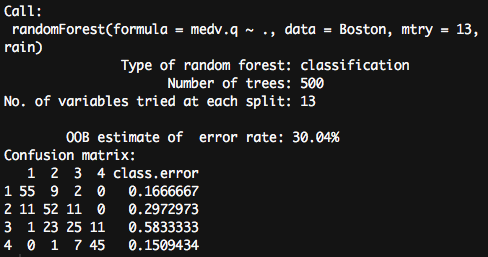
예측 성공률이 무려 70%에 육박하게 나왔다. 조금 더 뜯어보면, 해당 모델은 가장 비싼 집값의 그룹(medv.q = 4)을 맞추는데에 고작 15%정도의 오류율을 갖고 있다. 즉, 비싼 그룹이라고 판단하는 데에 그 예측 성공률이 85%라는 것이다.
해당 예측에 있어서 어떤 변수가 얼마나 좋은지에 대해서 그래프로 시각화할 수 있는데, varImpPlot() 함수를 통해보면, 아래와 같다.

varImpPlot(class.rf) 위의 그래프는 randomForest함수에서 인수 importance를 TRUE로 check하여 나온 결과이다. 만약 True가 아니라 False이거나 아예 인수를 적지 않는다면 그래프는 두 개로 출력된 위의 결과와 다르게 하나만 출력된다.
위의 결과를 해석해보면,
좌측의 MeanDecreaseAccuracy는 분류정확도를 개선하는데에 기여한 정도를 나타내는 지수이다. 높을수록 랜덤포레스트 모형 내에서 분류정확도에 기여했다는 뜻으로 볼 수 있다.
우측의 MeanDecreaseGini는 각 변수의 중요도를 나타내는 지수들 중 하나로, 랜덤포레스트에서 해당 변수로부터 분할이 일어날 때 불순도의 감소가 얼마나 일어나는지 나타내는 지수이다. 해당 값이 클수록 Purity가 올라 결국 '유의한 변수'라는 해석이 가능해진다. 불순도를 나타내는 지니지수는 회귀분석(regression)의 경우엔 잔차제곱합으로 계산되는 값이기도 하다.
해석해보면, lstatr과 rm이라는 변수가 해당 분류를 실행하는데 거의 대부분의 역할을 하고 있는 것으로 보인다. 해석 결과에 따라 해당변수만을 골라 다시 랜덤포레스트를 시행해보았다.

단 두 개의 변수만을 넣었는음에도 기존 예측률 70%에서 63%로 크게 훼손되진 않은 결과를 보여주었다.